My PhD Field Exam Materials
This past week, I submitted a draft of my field exam portfolio (the narrative statement and reading list). It’s helped me articulate my position in relation to larger scholarly fields. That’s worthy of wider discussion and further input, so I’m posting these materials here. Other PhD students gearing up for the field exam may find them useful, too. But at a minimum, I look forward to my future self re-discovering this post and remembering that middle phase of the PhD when I was really trying to understand what the hell I was doing 🙂
Field Exam: Digital Humanities, Cultural Analytics, & Natural Language Processing
Narrative Statement:
Let me begin by addressing the fact that there are three scholarly fields listed as the subject of my reading list: the digital humanities (DH), cultural analytics, and natural language processing (NLP). While it may seem as though I’m overindulging as a scholar, the reality is that I can’t accurately define my position without incorporating some facets of each field. Moreover, my intent is not to present a reading list that covers the entirety of each field on its own, but rather one that elucidates where these fields are coterminous–and in that space, to define my professional trajectory and research goals. These fields are undeniably unique in terms of their histories, scopes, and paradigms, but their relationships should become clear when presented as confluences to my own work and those works in my reading list.
Yet I also don’t think it’s particularly contentious to recognize the cross-pollination of these fields–to note that their practitioners and projects demonstrate innovation or interest in ways relevant to each other. To argue the centrality of one within the other, however–to imagine their coterminous boundaries as concentric circles where DH is the largest, cultural analytics resides in the middle, and NLP is the smallest–that’s admittedly subjective (see Figure 1). But again, in the context of my field exam, that subjective understanding parallels my scholarly background, and it points toward my likely trajectory, since I was first a digital humanist, then one interested in research about culture at scale, and finally, one who sought expertise in NLP. If my scholarly background followed the opposite pattern, I’d be willing to bet that Figure 1 would be in the opposite order, too. That’s just another acknowledgement that my own position informs how I understand the shared space of these fields. The conception in Figure 1 should therefore be understood as more descriptive of my place in the milieu of cross-pollinating scholarly work than prescriptive of the fields themselves.
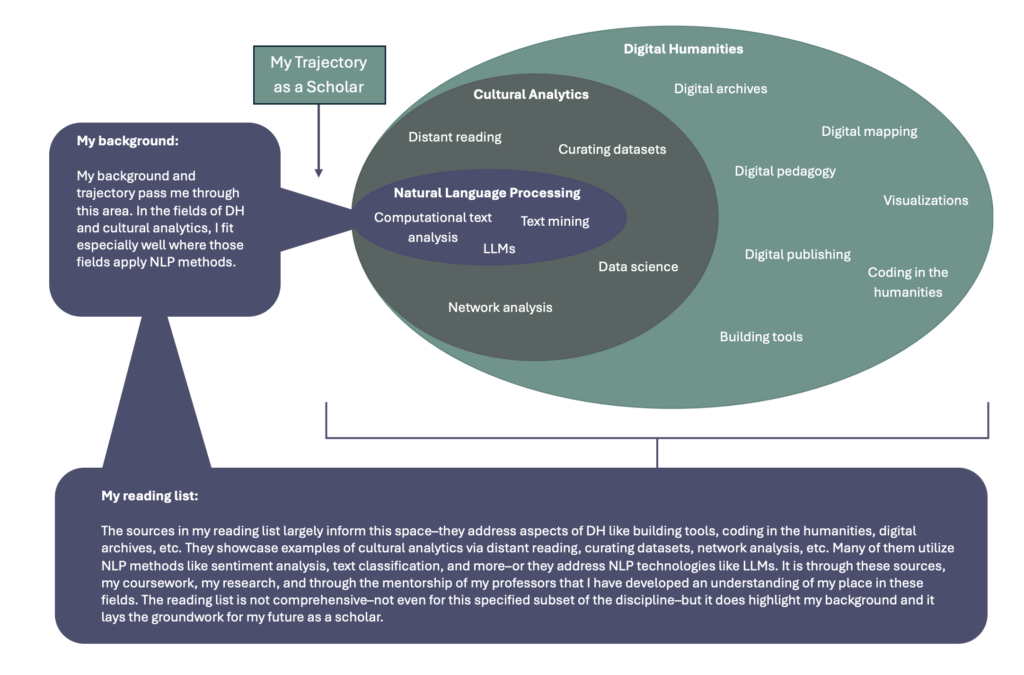
Represented in Concentric Circles
But how did I get here? A proper explanation begins before I entered the PhD program. It was during my MFA in Creative Writing that I was exposed to digital tools like Voyant, concepts like literary mapping, and new modes of digital publication. These experiences were rarely the focal points of my coursework, but they piqued a high degree of interest–so much so that I went beyond the curricular expectations of the MFA to engage with them. At the same time, I was afforded the resources, mentorship, and feedback necessary to develop a strong command of written language. In the context of the MFA, the purpose of that support was to hone my writing abilities, but it no less gave me a fuller picture of the capacities (and limitations) of written language from technical and theoretical perspectives as well. That foundation is undoubtedly why my trajectory in the larger field of DH aligns with its subsets of research that utilize NLP methods. In other words, my experiences as a writer and MFA graduate afford me a better understanding of language as data.
This remained true as I completed another graduate degree–an MA in Literary Studies with a Graduate Certificate in DH. It was through this more DH-focused curriculum that I discovered the larger scope of the field. I read a variety of works in DH classes and I took part in digital editing projects and I worked on pedagogical resources in DH. I started programming for the first time, too, and began to understand on a more granular level the kinds of largescale cultural analytics projects and monographs that form some of my reading list. During this period of my scholarly development, I also learned more about scrutinizing data, the relevance of digital archives and the processes from which they produce data, and the specific computational challenges of processing natural language. The MA in Literary Studies also foregrounded my subject interests. It meant that I could serve as a subject specialist in U.S. literary history on any DH projects moving forward.
But what remained was a need to develop my technical understanding and coding abilities in order to enact the kinds of research I aspired to. In that regard, the PhD program in the iSchool has been especially crucial. Through the PhD coursework, I’ve studied more DH and cultural analytics texts and projects, but this time with experiential modalities, providing a foundation for my computational work and my future research applying rigorous NLP methods. For example, I’ve been able to build data curation pipelines that incorporate Named Entity Recognition (NER). I’ve learned how to conduct text classification experiments to study things like genre, tone, or gender. I’ve practiced more computationally intensive methods of information retrieval. I’ve learned how to utilize visualizations–everything from bar graphs to geospatial maps. I was also fortunate to be in the coursework stage of the PhD when large language models (LLMs) suddenly became ubiquitous, and in turn, I’ve developed a much more technical (and holistic) understanding of that technology. In many ways, I’ve appreciated the PhD in Information Science as the period wherein I’ve unified my research interests, capabilities, and influences. One goal of this reading list is to demonstrate those aspects of my experience thus far, and through the written and oral exams, showcase my scholarly maturation within the field.
Which brings me to the reading list itself. Despite all this spatializing language about where these fields fold atop each other, I’ve chosen to group the reading list a little differently. That’s because I don’t want the fraught task of arguing which text is DH versus cultural analytics versus NLP–and honestly, that would be missing the point since my argument is that they are not mutually exclusive under the relational conditions of my field exam (and my trajectory as a scholar). So, rather than using those categories to segment my reading list, I’m instead segmenting it into four loose categories defined by their critical considerations of the field. Those four categories are 1) Implementation (Contextualizing & Defining Methods), 2) Subject Matter (Contextualizing & Defining Data), 3) Applications (Tools & Projects), and 4) Potential Futures (LLMs & Ubiquitous NLP). Those section titles are not completely self-explanatory, so let me conclude by expanding on each one in the following outline. After reading, it should be clear how these categories are unified in themselves, and how they relate to one another.
- Implementation (Contextualizing & Defining Methods):
The texts in this category have proven especially valuable for their ability to define and/or contextualize NLP methods in DH contexts. They address issues of conflicting paradigms, procedures, and institutional support. They recognize the inherent challenges of the coterminous boundaries of DH, cultural analytics, and NLP. They are useful demonstrations of how and where challenges arise when applying NLP methods to DH research, especially at scale.
- Subject Matter (Contextualizing & Defining Data)
The texts in this category are especially valuable because they emphasize that the subject matter of NLP-driven work is defined as much by its textual data as it is the cultural phenomena those textual data are meant to represent. These works describe textual datasets, describe how they were constructed, and/or they question the capacity of data to represent the world. They address why and how we should qualify knowledge derived from NLP-driven research in cultural analytics and DH.
- Applications (Tools & Projects)
Admittedly, this is the most unstable category in the list. It is composed of texts and projects that demonstrate how NLP-driven work can be implemented in cultural analytics and DH. Many of the texts from the other categories belong here, too–things like Bode’s A World of Fiction, Klein’s “The Image of Absence”, Ehrett’s “Shakespeare Machine”, etc.–but those works showed equal (or better) value in the other categories, so I dispersed them accordingly. In any case, though, this category includes works that use NLP methods and/or discuss tools for using NLP methods in DH and cultural analytics in effective ways.
- Potential Futures (LLMs & Ubiquitous NLP)
This category is largely defined by the sociocultural and technological moment we find ourselves in. It contains works that critique LLMs or apply them in research. Here I’m considering LLMs a significant NLP technology–a technology that needs to be questioned as much as it is applied, a technology that shows promise for future work, but also has undertheorized limitations and consequences. I’ve chosen to include this category because I imagine it will be a subject I have to reconcile from my scholarly position over the next several years (or perhaps throughout the rest of my career). That may sound like I’m worried about the future of LLMs in DH and cultural analytics, but that’s not entirely true. I have equal parts apprehension and excitement. This category tries to account for both.
Reading List:
Section 1: Implementation (Contextualizing & Defining Methods)
- Da, Nan Z. “The Computational Case against Computational Literary Studies.” Critical Inquiry, vol. 45, no. 3, Mar. 2019, pp. 601–39. DOI.org (Crossref), https://doi.org/10.1086/702594.
- Kirilloff, Gabi. “Computation as Context: New Approaches to the Close/Distant Reading Debate.” College Literature, vol. 49 no. 1, 2022, p. 1-25. Project MUSE, https://doi.org/10.1353/lit.2022.0000.
- Piper, Andrew. “There Will Be Numbers.” Journal of Cultural Analytics, May 2016. DOI.org (Crossref), https://doi.org/10.22148/16.006.
- Ramsay, Stephen. Reading Machines: Toward an Algorithmic Criticism. University of Illinois Press, 2011.
- Rhody, Lisa Marie. “Why I Dig: Feminist Approaches to Text Analysis.” Debates in the Digital Humanities 2016, edited by Lauren Klein and Matthew K. Gold, University of Minnesota Press, 2016, https://dhdebates.gc.cuny.edu/read/untitled/section/508c8664-15c8-4262-a72a-e49299873d11#ch46.
- So, Richard Jean. “‘All Models Are Wrong.’” PMLA, vol. 132, no. 3, 2017, pp. 668–73. JSTOR, https://www.jstor.org/stable/27037381. Accessed 18 July 2024.
Section 2: Subject Matter (Contextualizing & Defining Data)
- Bamman, David, et al. “An Annotated Dataset of Literary Entities.” Proceedings of the 2019 Conference of the North, Association for Computational Linguistics, 2019, pp. 2138–44. DOI.org (Crossref), https://doi.org/10.18653/v1/N19-1220.
- Bode, Katherine. A World of Fiction: Digital Collections and the Future of Literary History. E-book, Ann Arbor, MI: University of Michigan Press, 2018, https://doi.org/10.3998/mpub.8784777.
- Clement, Tanya. “The Ground Truth of DH Text Mining.” Debates in the Digital Humanities 2016, edited by Lauren Klein and Matthew K. Gold, University of Minnesota Press, 2016, https://dhdebates.gc.cuny.edu/read/untitled/section/ef78ddc7-4087-4bb3-b192-16724631a172#ch45.
- Cordell, Ryan. “‘Q i-Jtb the Raven’: Taking Dirty OCR Seriously.” Book History, vol. 20, no. 1, 2017, pp. 188–225. DOI.org (Crossref), https://doi.org/10.1353/bh.2017.0006.
- Klein, Lauren. “The Image of Absence: Archival Silence, Data Visualization, and James Hemings.” American Literature, vol. 85, no. 4, Dec. 2013, pp. 661–88. DOI.org (Crossref), https://doi.org/10.1215/00029831-2367310.
- Lee, Benjamin. “Compounded Mediation: A Data Archaeology of the Newspaper Navigator Dataset.” DHQ, vol. 15, no. 4, 2021, https://www.digitalhumanities.org/dhq/vol/15/4/000578/000578.html.
Section 3: Applications (Tools & Projects)
- Cordell, Ryan, et al. Going the Rounds: Virality in Nineteenth-Century American Newspapers. University of Minnesota Press, https://manifold.umn.edu/projects/going-the-rounds.
- Hengchen, Simon, et al. “A Data-Driven Approach to Studying Changing Vocabularies in Historical Newspaper Collections.” Digital Scholarship in the Humanities, vol. 36, no. Supplement_2, Nov. 2021, pp. ii109–26. DOI.org (Crossref), https://doi.org/10.1093/llc/fqab032.
- Jockers, Matthew. Macroanalysis: Digital Methods and Literary History. University of Illinois Press, 2013. JSTOR, http://www.jstor.org/stable/10.5406/j.ctt2jcc3m. Accessed 12 July 2024.
- Long, Hoyt, and Richard Jean So. “Literary Pattern Recognition: Modernism between Close Reading and Machine Learning.” Critical Inquiry, vol. 42, no. 2, 2016, pp. 235–67.
- Mullen, Lincoln A. America’s Public Bible: A Commentary. Stanford University Press, 2023. DOI.org (Crossref), https://doi.org/10.21627/2022apb.
- Santin, Bryan, et al. “Is or Are: The ‘United States’ in Nineteenth-Century Print Culture.” American Quarterly, vol. 68, no. 1, Mar. 2016, pp. 101–24. DOI.org (Crossref), https://doi.org/10.1353/aq.2016.0011.
- Rockwell, Geoffrey, and Stéfan Sinclair. Hermeneutica: Computer-Assisted Interpretation in the Humanities. The MIT Press, 2017.
- Soni, Sandeep, et al. “Abolitionist Networks: Modeling Language Change in Nineteenth-Century Activist Newspapers.” Journal of Cultural Analytics, arXiv:2103.07538, arXiv, 12 Mar. 2021. arXiv.org, http://arxiv.org/abs/2103.07538.
- So, Richard Jean. Redlining Culture: A Data History of Racial Inequality and Postwar Fiction. Columbia University Press, 2021.
- Underwood, Ted. Distant Horizons: Digital Evidence and Literary Change. The University of Chicago Press, 2019.
- Wilkens, Matthew, et al. “Small Worlds: Measuring the Mobility of Characters in English-Language Fiction.” Journal of Computational Literary Studies, Sept. 2024. DOI.org (Datacite), https://doi.org/10.48694/JCLS.3917.
Section 4: Potential Futures (LLMs & Ubiquitous NLP)
- Bamman, David, et al. “On Classification with Large Language Models in Cultural Analytics.” arXiv, 2024. DOI.org (Datacite), https://doi.org/10.48550/ARXIV.2410.12029.
- Bender, Emily M., et al. “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜.” Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, ACM, 2021, pp. 610–23. DOI.org (Crossref), https://doi.org/10.1145/3442188.3445922.
- Chang, Kent K., et al. “Speak, Memory: An Archaeology of Books Known to ChatGPT/GPT-4.” 2, arXiv, 2023. DOI.org (Datacite), https://doi.org/10.48550/ARXIV.2305.00118.
- Ehrett, Carl, et al. “Shakespeare Machine: New AI-Based Technologies for Textual Analysis.” Digital Scholarship in the Humanities, vol. 39, no. 2, June 2024, pp. 522–31. DOI.org (Crossref), https://doi.org/10.1093/llc/fqae021.
- Klein, Lauren. “Are Large Language Models Our Limit Case?”. Startwords, Aug. 2022. DOI.org (Datacite), https://doi.org/10.5281/ZENODO.6567985.
- Underwood, Ted. “Mapping the Latent Spaces of Culture.” Knowledge Commons, 2021, http://dx.doi.org/10.17613/faaa-1r21.
- Walsh, Melanie, et al. “Does ChatGPT Have a Poetic Style?” arXiv:2410.15299, arXiv, 30 Oct. 2024. arXiv.org, https://doi.org/10.48550/arXiv.2410.15299.
