Academic Research
This page includes links to my various academic research projects. Some send you outbound to the official project websites. Others will point you to my blog posts covering these projects in greater detail.
If you’d like to discuss any of these works, please feel free to contact me.
Virality of Racial Terror Project
Forthcoming.
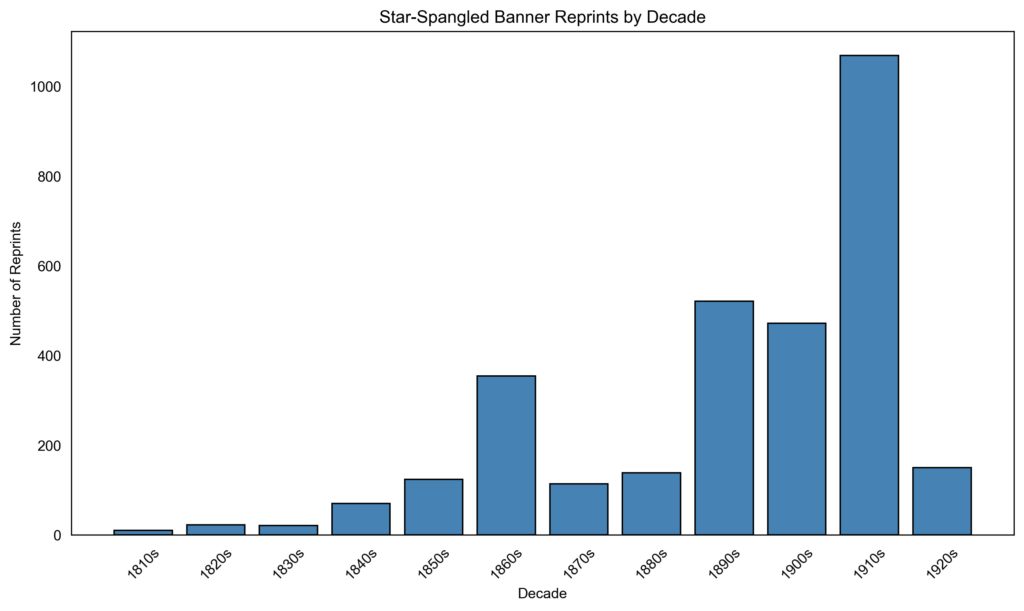
The Viral Texts Project
My first foray into the Viral Texts Project–deduplication and the Star-Spangled Banner.
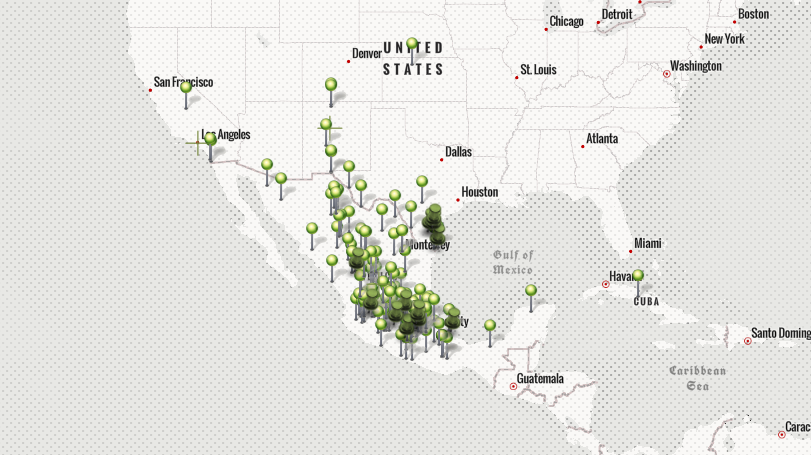
Folklore, Place, and Song: Digital Ethnomusicological Mapping of Corridos
A data curation, mapping, and textual study on corridos, the traditional Mexican genre of folksong.

MA Thesis: The U.S. Local Color Corpus
A data curation and textual analysis of U.S. local color and regionalist fictions from the 19th and 20th centuries.