Academic Research
I’m a digital humanist and information scientist with a background in U.S. literary history and creative writing. My research is guided by my background but applies novel methods drawn from natural language processing (NLP), cultural analytics, and machine learning to answer questions about U.S. literary history, texts, and culture. In particular, I’m interested in regionalisms–defined as cultural and artistic nexus of association bound by place–and their roles in literary history. Yet as a technology enthusiast, I also spend equal measure of time studying the computational underpinnings of many research approaches in the digital humanities, trying always to find new ways to apply digital tools and methods in my work. By necessity (and genuine interest), I also study print history, bibliography, print technology, and digitization, as these subjects define the data I use in research.
I’ve also been an undergraduate writing instructor for nearly a decade. I’ve taught undergraduate writing courses at the University of Nevada, Las Vegas, at Washington State University, and now at the University of Illinois, Urbana-Champaign. I adhere to process pedagogies and backward design, and I try to incorporate practical applications of digital tools into my lessons so students can reapply their writing experiences across mediums and contexts.
Below are some of my more recent projects. If you’d like to learn more about my work or my teaching experiences and approaches, feel free to Contact me.
Viral Texts Project
I’ve worked with my advisor, Professor Ryan Cordell, on the Viral Texts Project for two semesters. The Viral Texts Project applies text-mining, NLP, and network analysis methods to the study of textual data from nineteenth century newspapers in order to understand how and why certain texts or themes circulated widely during the period. As a research assistant on the project, I’ve helped to consider approaches, identify subject matter worthy of investigation, and theorize the efficacy of certain computational methods.
In my first semester with Viral Texts, I assisted with an ongoing research project that aims to measure euphemistic and propagandist language in U.S. newspapers just before, during, and after the American Civil War. The project applies word embedding models to a corpus of newspapers categorized by their political affiliations. The ultimate goal is to make new arguments about (and identify new methods of measurement for) euphemism as a rhetorical strategy during the Civil War.
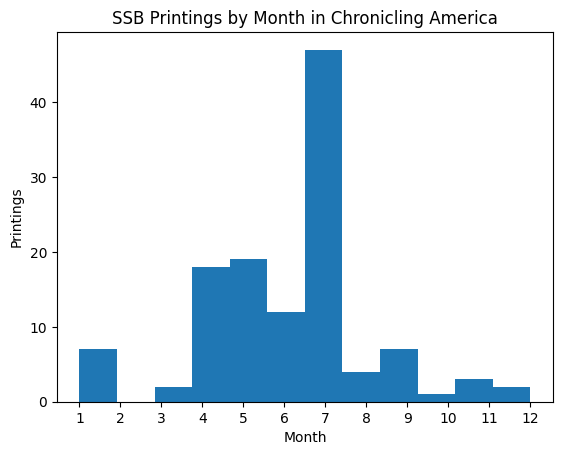
Yet more recently, I’ve been focused on deduplication–a sometimes necessary (and often overlooked) step in the preprocessing of textual data from nineteenth century newspapers. There’s an irony to this project as Viral Texts is typically concerned with reprints–with identifying, measuring, and maintaining their instances–and yet we also often need to deduplicate texts as part of our data preprocessing.
To this end, I’m surveying recent DH and NLP scholarly work that includes deduplication, or neglects to do it. At the same time, I’m describing several methods of deduplication and highlighting how or to what degree they would be effective, depending on the research questions being asked and the NLP models being applied. I demonstrate these theoretical and methodological considerations with a dataset of nineteenth century newspapers that reprinted the “Star-Spangled Banner”.
There have been some interesting findings so far, but the bulk of the work is ongoing. Still, we have established two primary arguments: 1) deduplication should be a transparent step in most text-mining processes, and 2) effectively deduplicating requires a deep understanding of the materiality of textual sources of data, especially nineteenth century newspapers.
Folklore, Place, and Song: Mapping Corridos Across Mexico and the American Southwest
Folklore, Place, and Song is a collaborative digital project involving Named Entity Recognition (NER), geomapping of textual data, and cultural data curation.
We compiled a dataset of corridos–narrative songs of Mexico–and mapped their references to place, their performance or recording locations, and/or their publisher locations. The result is an interactive map that allows users to explore how corridos define place through their dissemination, performance, and through their textual references.
Feel free to explore the map below. You can also visit https://corridos.omeka.net/ for more info.
Our metadata and code can be found at https://github.com/MatthewKollmer/corridos.
The U.S. Local Color Corpus (USLoCo)
My MA thesis at Washington State University involved theorizing and constructing the U.S. Local Color Corpus (USLoCo)–a dataset meant to assist in the research processes of scholars interested in U.S. local color or regionalist fictions. In its current iteration, USLoCo is composed of 730 short stories, novellas, and serialized novel chapters that were published between 1865 and 1920. A total of 46 authors are represented in the corpus. Each text is categorized by the author’s race and gender and by various regional settings (by state, subregion, and ecoregion). All texts have been cleaned and saved as .txt files, making them ready for computational analysis. You can download the corpus from my GitHub repository. More information about it can be found in my MA thesis, published via ProQuest. You can also explore the corpus in Voyant (see below). This project is open-source and available for anyone interested.
The U.S. Local Color Corpus (USLoCo) in Voyant